
In recent years, there has been a new movement in biology and especially in phylogenetics, which looks at the carbon footprint of our computational analyses. It is called green computing or green phylogenetics. Especially supercomputers have a high energy demand, not only for the actual calculation, but also for the cooling of the supercomputer. Sudhir Kumar covered this topic in the article “Embracing Green Computing in Molecular Phylogenetics” this year in Molecular Biology and Evolution.
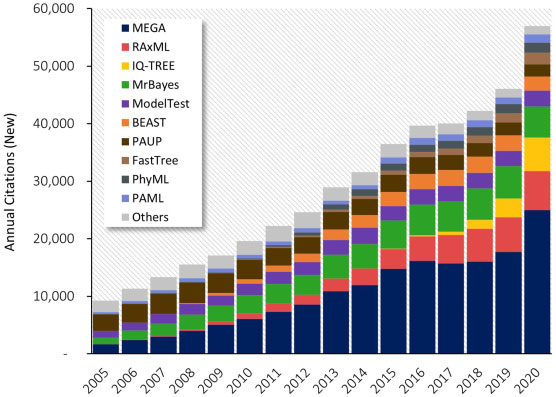
articles citing major software packages for molecular evolutionary and phylogenetic analyses.
In the paper, he first shows that the computational demands for phylogenetics are steadily increasing. Phylogenetic trees are the basis for more and more analyses in different research fields and hence are included in an increasing number of papers. Datasets are also becoming bigger as they are now often based on genome-scale data. This approach is also called phylogenomics. Moreover, we apply increasingly more sophisticated methods to better describe the complicated evolutionary history of molecular data.
He then shows different approaches how we might be able to reduce our carbon footprint by using “methods, algorithms, and software practices that demand fewer compute cycles and less computer memory”. He discusses possible options for this in model selection, in the tree reconstruction itself, in calculation of support values and in molecular dating. Different possibilities are also assessed in the paper with respect to computational resources with respect to time and memory and based on the energy consumption and how many days a tree would need to filter the carbon out the air again. The paper was very interesting and got one to think about the carbon footprint our analyses are having. On the other hand, there is also the scientific principal that we should thrive to get the answer, which is most likely to be correct. Taking caveats for fast computations have a higher chances for being misled. Hence, it will still be a process of consideration between energy consumption and accuracy.

After we had discussed the paper in the journal club, I checked at Green Algorithms what the energy consumption of my projects had been in 2020. 2020 was the year with our highest computational demand so far. We had used on the Norwegian Supercomputer Abel 544132 CPU hours with 1 core and 4 GB on average. The carbon footprint was 62 kg CO2. This relates almost 6 tree-years or a little more than one flight (1.2) from Paris to London. The other comparison provided by the webpage is driving with a passenger car 355 km. This is roughly driving once from Oslo to Kristiansand in Norway or from Frankfurt to Munich in Germany. Hence, all in all the footprint is not too large at the larger scale.
However, a huge advantage is that these computations were done in Norway. The exact same analyses conducted in Germany would have resulted in 2.8 tons CO2, 251 tree-years, 16000 km in a car or more than a flight (1.2) from New York to Melbourne. In the USA, it would have been 3.5 tons CO2, 315 tree-years, 20000 km in a car or one and a half flight from New York to Melbourne. Finally, in Australia it would have been 6.9 tons CO2, 624 tree-years, 39000 km in a car or three flights from New York to Melbourne (see featured image at the top). This shows that while it is important to work on optimizing the energy consumption of our computations, more importantly, it is necessary that the energy is generally generated without producing carbon. While energy in Norway is predominantly generated from water, it is coal in Australia.
![]()